:focal(smart))
50x faster solves with sharded repodata
Pixi can now solve many complex conda environments up to 50x faster with a new method to acquire repodata. This will not only speed up daily usage of pixi but also CI workflows. This blog takes a deep dive into the technical details of how we achieved that. Read on to learn more!
pixi update (old repodata)
pixi update (new repodata)
Introduction
When solving which packages are needed in a conda environment the solver requires knowledge about the packages that exist. Different ecosystems take different approaches but for the conda ecosystem indexes exist that provide information about all packages that exist in a certain channel. We call this information repodata.
Historically, for each supported platform in a channel, a single file exists called repodata.json. This file encodes the information needed by a solver for every available package for that platform in that channel (called a subdir). Every time you upload a new package to a channel this file gets updated with the information from your newly uploaded package. Historical data is never removed, so this file grows linearly with the number of packages stored in the channel.
Some channels have become quite large. The popular conda-forge channel contains roughly 1.5 million packages for roughly 25.1 thousand unique package names. The repodata.json files of the largest subdirectories have grown substantially as can be seen in this table.
subdir | records | size |
|---|---|---|
linux-64 | 465 679 | 243 MB |
osx-64 | 413 499 | 206 MB |
win-64 | 301 555 | 154 MB |
noarch | 190 480 | 87 MB |
osx-arm64 | 126 443 | 71 MB |
When using our software package management tool pixi you often need to resolve your environments and we have put significant effort into making this extremely fast with great success. However, we have always been annoyed by how slow it is to acquire repodata. So to improve this, we have come up with a new method of acquiring repodata that is much faster than current solutions and simpler for server infrastructure too.
Previous attempts to speed up repodata loading
Because the repodata.json is just one file, a user will need to redownload this file, every time a new package is added. As a result most channels only update the repodata.json once about every hour. This makes it easier on the infrastructure because it enables better caching and users no longer have massive updates every time they create or update a conda environment. However, the downside of this approach is that it can take quite some time before your newly uploaded package is available to other users or CI systems.
Over the years several methods to reduce the time required to acquire repodata have been proposed and implemented.
Simply don’t store all records
Another approach that was introduced several years ago was to not give the solver all the information but instead have a special current_repodata.json that only contains the latest versions of packages. Since the size of this file scales with the number of unique package names and not with the number of packages added this file can be drastically smaller. In the case of conda-forge this would be 25.1 thousand entries vs 1.5 million. Roughly ~1.6% of the original size. This can also significantly improve the solver’s performance because the search space becomes substantially smaller.
However, the obvious downside is that if a package requires an older version of a package than the latest version then the solver will not be able to find a solution. In practice, this happens a lot which makes this method far from ideal.
Compression
Another way to reduce the time it takes to acquire repodata is to compress the repodata.json files. Initially, this was done during HTTP transport. When the HTTP server would serve a repodata.json file it would encode the file on the fly using gzip . This reduces the overall download to around 15%-30% of the original size, a significant reduction! However, HTTP servers would be limited by the compression speed which reduces the overall transfer speeds to 5MB/s. On high bandwidth connections, this can be quite the bottleneck.
As an alternative, servers store a pre-compressed file using bz2 or the later introduced zst . Older conda clients would not be able to work with compressed files yet, so new filenames were added, repodata.json.bz2 and repodata.json.zst respectively.
subdir | records | uncompressed size | bz2 size | zst size |
|---|---|---|---|---|
linux-64 | 465 679 | 243 MB | 33.9 MB (14%) | 32.5 MB (13%) |
osx-64 | 413 499 | 206 MB | 30.1 MB (15%) | 28.8 MB (14%) |
win-64 | 301 555 | 154 MB | 21.6 MB (14%) | 20.9 MB (14%) |
noarch | 190 480 | 87 MB | 13.8 MB (16%) | 13.8 MB (16%) |
osx-arm64 | 126 443 | 71 MB | 10.0 MB (14%) | 9.0 MB (13%) |
Using these pre-compressed files HTTP servers can fully use their available bandwidth which significantly reduces the time required to acquire repodata.
However, even with compression and caching enabled users are still required to re-download all the repodata.json files regularly to get the latest available packages. If a user is solving for a Linux environment the total download size still amounts to ~46.3 MB (linux-64 + noarch). On a decent 200 mbit connection this still takes 1.8 seconds at best and this is not taking into account decompressing and parsing the JSON.
With pixi, you often want to solve for more platforms than just Linux, so in the worst case a user needs to re-download the repodata for all subdirectories (105 MB).
JLAP - JSON patches
All of the above methods still have this downside that whenever someone uploads a new package (any package!), the entire repodata.json file needs to be recreated and re-downloaded by users. But what if we could only download the changes to the repodata.json instead?
That is what the JLAP proposal set out to do. JLAP was introduced as a Conda Enhancement Proposal (CEP) and multiple client and server side implementations exist. Both conda and rattler (the library powering pixi), have working implementations. Even the official conda servers support it. However, the CEP has not yet been accepted and JLAP support has not made it past being an experimental feature in conda. To understand why, we first have to look at how JLAP works.
JLAP, or JSON Patch Incremental Updates, utilizes JSON Patch to update a previously downloaded repodata.json file. In a nutshell the repodata.json.jlap file is an append-only file that stores incremental updates to the repodata.json file. The client remembers which patches in the .jlap file were last applied, downloads any newly available patches, reads and applies the JSON patches to the repodata.json file, and writes it back out for later use. There is some more fanciness happening with checking hashes of the file but the basic algorithm is just that.
The upside of this approach is that even though a user has to download the repodata.json files once, every subsequent time only the patches have to be downloaded. The patches are small which makes them very fast to download and thus saves a lot of time.
However, even though applying JSON patches is quite fast, serializing and deserializing the massive amount of JSON can be quite slow (in the order of seconds). You are trading bandwidth for compute. It takes much less time to download the file but it takes more time to process the information.
On the server-side it also complicates things because now instead of being a stateless process an “indexer” also needs to keep track of the previous versions of the repodata it served.
Furthermore, this approach only helps when a user already has a lukewarm cache, e.g. they previously downloaded a repodata.json file. In CI systems this is often not the case and the entire repodata.json needs to be downloaded from scratch.
Finally, the implementation of JLAP is relatively complex. It requires juggling hashes, implements a custom file format (the .jlap file), and requires synchronizing state to disk in an environment where multiple clients might be running at the same time.
Our new method
As we have seen, all of the current methods of reducing the time to acquire repodata have downsides. We need something better.
We want to have a solution that:
.. is very fast to download and process. Both in the hot- and cold-cache case.
.. makes all repodata available, not just the latest version
.. can be “indexed” quickly to allow servers to update as soon as a new package becomes available.
.. can be used with a CDN to reduce the operating cost of a channel.
.. supports authentication and authorization with little extra overhead.
.. is straightforward to implement to ease adoption in different clients.
Our new method fulfills all of the above requirements. Lets dive into how it works.
Introducing the sharded index
A sharded index splits up the original repodata into several files. It is based on the fact that even though new packages get added quite often, only a very small percentage of all the unique packages are updated.
We split up the repodata.json file into an index and a shard per package name.
Shards
Each shard is stored in a content-addressable fashion, e.g. the filename is the SHA256 hash of the content. Each shard contains all repodata for a single package name. The data is encoded using msgpack and compressed with zst.
Note
We chose msgpack because it produces slightly smaller files and is faster to decode than JSON files. There are also implementations of msgpack available for a wide variety of programming languages often with an API that is a drop-in replacement for JSON.
The index file
The index is a file that encodes for every package name the corresponding SHA256 hash of the corresponding shard and some metadata. This file is also encoded with msgpack and compressed with zst.
The index file itself is still updated whenever a new package is uploaded and thus it requires re-downloading by a user. However, the size of this file scales with the number of unique package names, not with individual packages. This makes the file quite small in practice:
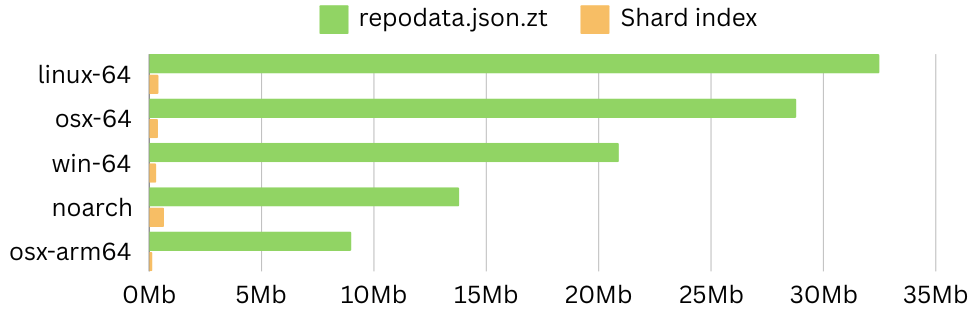
subdir | records | repodata.json.zst | shard index |
|---|---|---|---|
linux-64 | 465 679 | 32.5 MB | 0.421 MB |
osx-64 | 413 499 | 28.8 MB | 0.391 MB |
win-64 | 301 555 | 20.9 MB | 0.319 MB |
noarch | 190 480 | 13.8 MB | 0.666 MB |
osx-arm64 | 126 443 | 9.0 MB | 0.146 MB |
The basic algorithm
The basic algorithm is as follows:

Download a token file to authenticate with the server. Any form of authentication can be used to acquire this file. The returned token is then used to authenticate subsequent requests.
Download (or read from cache) the index file.
For each package that is missing repodata, download (or read from cache) the repodata
Parse the repodata to determine the package names of all dependencies
Go back to 2 to process any newly discovered package name.
Caching
Note that we can apply very aggressive caching. Due to the nature of content-addressing the individual shard files are immutable. There is no need to contact the server to see if a shard is up-to-date or not. If the content of a shard changes, its hash changes. This means that if we have a shard available locally for a given hash we know it’s up-to-date.
Results
We have implemented this method in rattler and pixi, we implemented a server that mirrors conda-forge, and we wrote a Conda Enhancement Proposal to bring the sharded repo into the wider conda ecosystem.
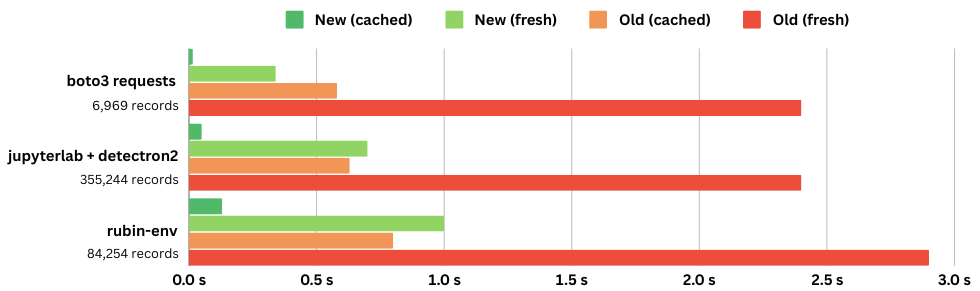
We profiled our implementation in rattler using the server we setup and got the following results. Our test is requesting repodata records for a specific set of packages from the linux-64 and noarch subdirectories. This is measured on a machine with a 200mbit internet connection.
requested packages | records | fresh | cached | sharded (fresh) | sharded (cached) |
|---|---|---|---|---|---|
python + boto3 + requests | 6969 | 2.4 s | 0.58 s | 0.34 s | 0.015 s |
jupyterlab + detectron2 | 35524 | 2.4 s | 0.63 s | 0.70 s | 0.05 s |
rubin-env | 84254 | 2.9 s | 0.80 s | 1.00 s | 0.13 s |
Note
We did not enable JLAP in these tests. With the extra processing required, it takes less time to just redownload the whole repodata.json.zst file. This is because the tests were run on a machine with a relatively fast internet connection speed.
Notice that both in the hot- and cold-cache case our new method significantly outperforms previous methods. This is mostly because even in complex cases (like rubin-env) you often only need a small percentage of the total repodata.
The performance of our method also remains more stable over time. If a new package is added, the complete repodata needs to be re-downloaded with old methods whereas with the sharded index we only need to re-download the small index file and the shards for updated packages. Most likely this is a fraction of the total packages, and most shards will already be cached.
The sharded index is also beneficial with slower internet connections because there is less data to transfer. Here are some results when the tests are run on a slow internet connection (requesting jupyterlab + detectron2 = 35524 records):
2 mbps | 10 mbps | 500 mbps | |
|---|---|---|---|
repodata.json.zst | 260 s | 102.0 s | 0.97 s |
Sharded index | 60 s | 9.3 s | 0.49 s |
Conclusion & future work
The sharded index ticks all the boxes of a solution that we were looking for:
Downloading the index and required shards is very fast.
All the repodata is still available through the individual shards.
Creating the necessary files on the server is relatively straightforward and can be done very quickly.
It is CDN friendly because its just static files (even the token can be a static file).
It supports authentication and authorization through the token file.
It is relatively straightforward to implement.
The CEP contains several improvements that we thought about like adding additional fields to the repodata that have previously been placed in separate files to keep the size of repodata down.
We hope that the CEP will be accepted by the wider conda ecosystem so that everyone can feel the benefits of the sharded index. And lastly we are already working with Anaconda to implement support for sharded repodata creation in conda-index.
How to use in pixi?
We are working towards getting these changes merged into rattler and pixi. When this work lands in the next release of pixi you will be able to use our sharded index mirror by simply replacing the conda-forge channel with https://prefix.dev/conda-forge :
[project] # ... channels = ["https://prefix.dev/conda-forge"] #channels = ["conda-forge"]
How you can help!
Although the results are very good, if the wider conda community does not adopt this method it will not become something that everyday users will benefit from. Without creating the necessary sharded files on the official conda servers it is not likely that this method will be adopted.
To help get more traction for the sharded index you can help us by leaving a thumbs up on the CEP, or sharing this blog on your favorite social network.
As always feel free to reach out on our social channels, we love to chat and help with any packaging related problems you are experiencing!
You can reach us on X, join our Discord, send us an e-mail or follow our GitHub.