:focal(smart))
Repodata patching: how conda-forge keeps compatible
mamba has become a popular package manager for scientific computing and data science projects. It simplifies the process of installing and managing software packages and their dependencies across various platforms.
One of the key components of mamba’s success is conda-forge, a community-driven repository that hosts thousands of open-source packages.
In this blog post, we will discuss the concept of repodata patching in conda-forge, how it works, and its benefits for users.
Understanding conda-forge
conda-forge is a community-driven effort that provides a vast collection of open-source software packages to mamba users. It is built on the premise of collaboration and aims to make package distribution and management more accessible and efficient. conda-forge uses a continuous integration and delivery (CI/CD) approach to build and distribute packages.
Repodata Patching
Repodata is metadata that describes all the packages in a repository, such as package versions, dependencies, and compatibility information. However, sometimes this metadata may contain errors or outdated information, which can lead to installation issues, dependency conflicts, or unexpected behavior. Repodata patching is the process of modifying repodata to correct errors or update information without rebuilding and redistributing the entire package.
This technique has become a valuable tool in the Conda-Forge ecosystem, as it allows the community to rapidly address problems and provide a smooth user experience.
How Repodata Patching Works
If you notice an inconsistency in the repodata (e.g. some package is not compatible with the newly released pandas 2.0) then repodata patching comes to the rescue! conda-forge has a fully automated special repository for this.
In this repository, a Python script generates a patched version of the full repodata json and produces the appropriate files. For example, suppose our package is called “mypkg”, we could change the upper bound of our pandas dependency from pandas >=1.5 to pandas >=1.5,<2 with the following Python code in the huge gen_patch_json.py
file:
if record_name == "mypkg": _replace_pin("pandas >=1.5", "pandas >=1.5,<2", record["depends"], record)
This will change the pandas pin for mypkg to the more appropriate version.
To test the changes, the conda-forge repository comes with a “show_diff.py” script. Invoking this script will print the diff of the changes from the online repodata to the repodata that was just patched. In our case, it would print something like
noarch::mypkg-0.10.0-pyhd8ed1ab_0.tar.bz2 - "pandas >=1.5", + "pandas >=1.5,<2",
It’s always helpful to include the output of the show_diff command in the PR that you might create in the repository.
Once the changes are merged, a Github action creates a new “conda-forge-repodata-patches” package that is uploaded to the channel. There it is picked up automatically by the indexing and the patches are applied. As of today, there are over 1220 versions of this package in the channel – a lot of patching!
Benefits of repodata patching
Faster updates: Since repodata patching only involves updating the metadata and not the package files, it is significantly faster than rebuilding and redistributing an entire package. This allows for quicker issue resolution and a better user experience.
Reduced bandwidth usage: Because only the repodata is updated, users do not need to download new versions of packages. This can save bandwidth and reduce the strain on the Conda-Forge repository's infrastructure.
Improved compatibility: Repodata patching can help resolve dependency conflicts or compatibility issues between packages, leading to a more stable and predictable environment for users.
If patching doesn’t help - mark as broken
Packages on conda-forge can be marked as broken - that removes (yanks) them from the repodata. This should be done if the contents of the package are bad, e.g. if the program always crashes with a segmentation fault. The package is still available for download, but won’t be considered at all by the solver. This ensures that environments with locked dependencies can still recreate that environment exactly, but new environments won’t take the broken package into account. The process to mark packages as broken is slightly different (by adding an entry to another special conda-forge repository, the admin-request repo). The full process is described very well on the conda-forge docs.
Repodata patches on prefix.dev
At prefix.dev we added some handy visualizations to the packages to show packages that were patched or “yanked” (marked as broken). For example, the lemon package has a few versions that didn’t work well:
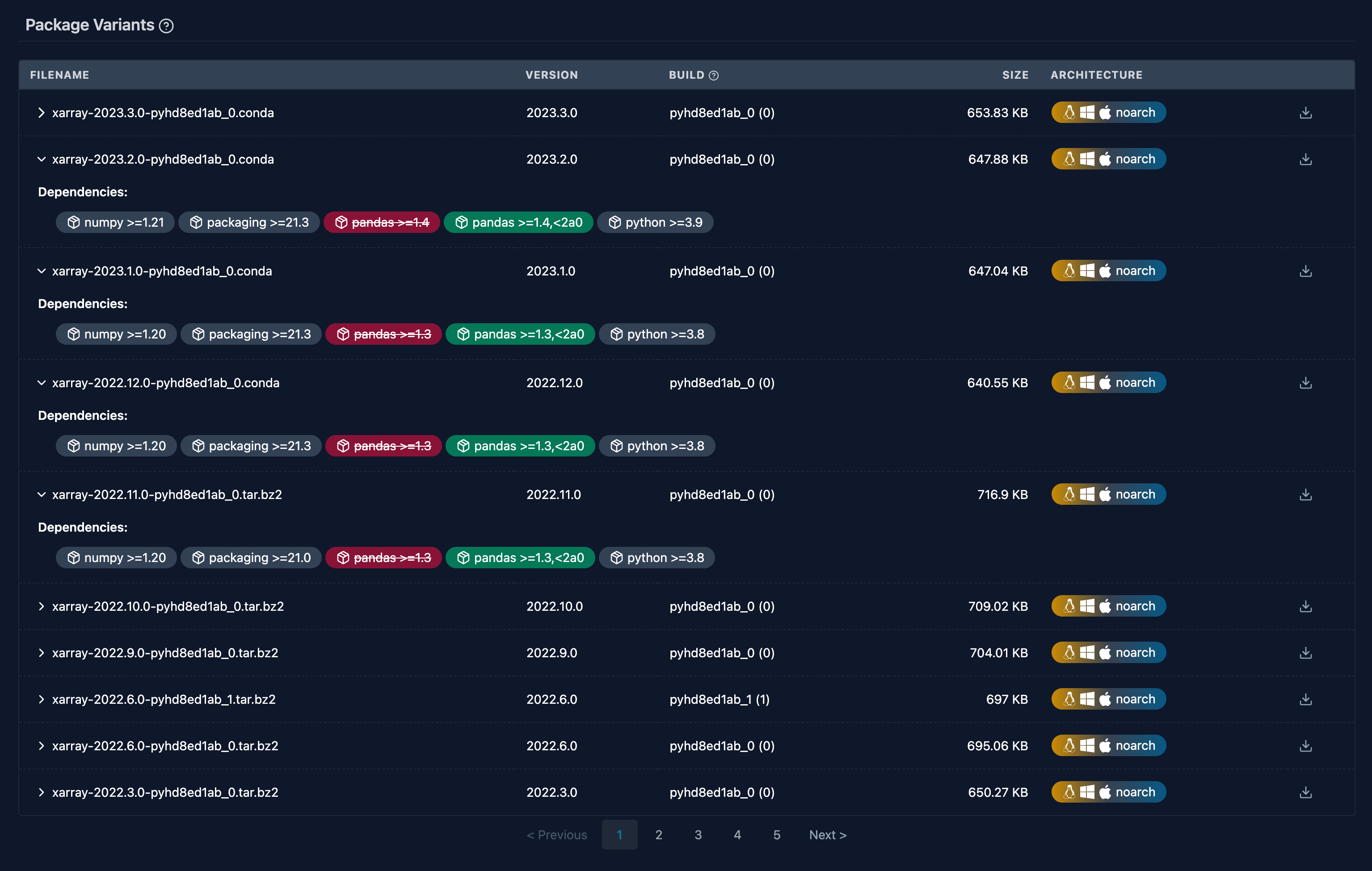
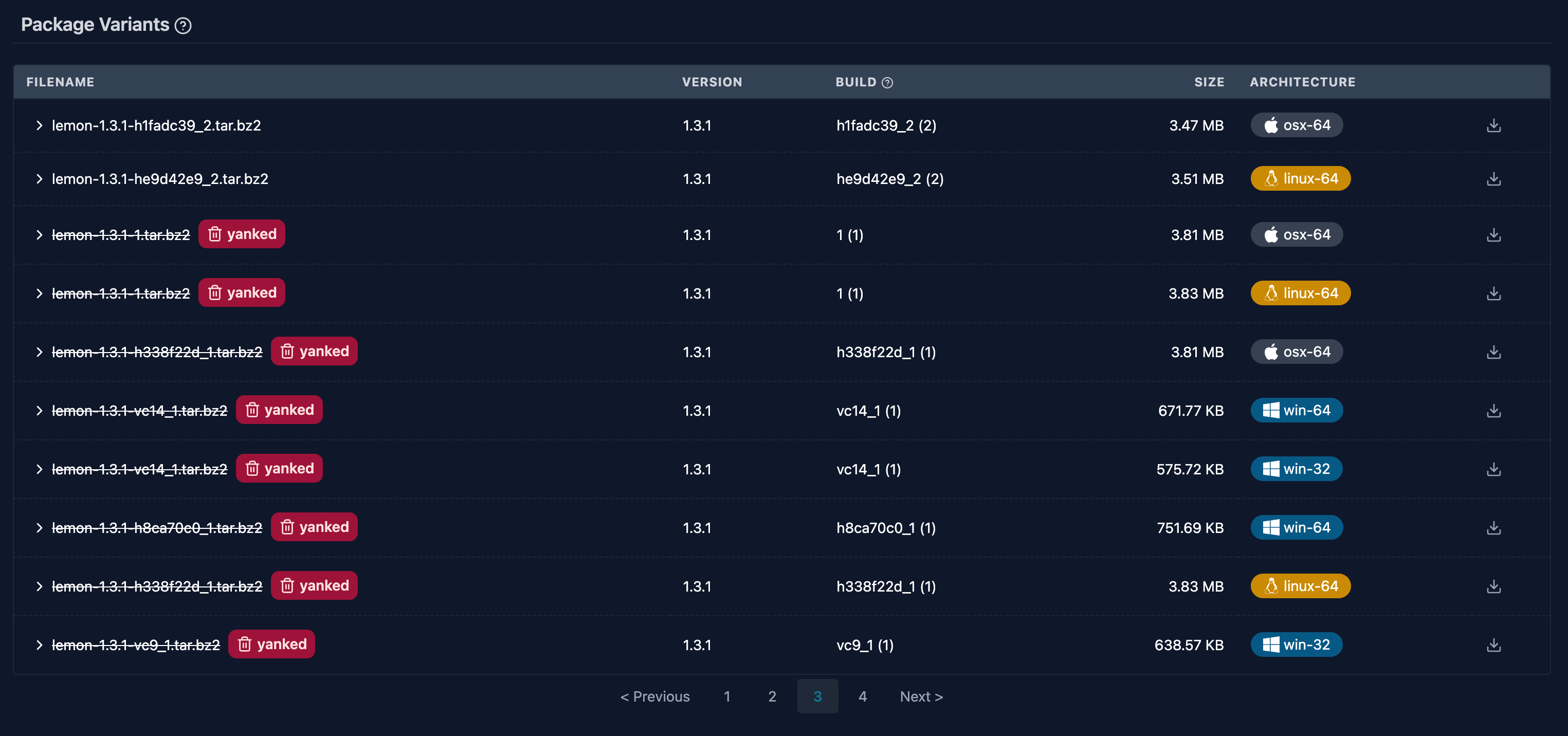 The situation (with the pandas 2.0 release) was actually a reason for some patches in “real-life” and we can see them nicely on prefix.dev! The read pandas pin of xarray (
The situation (with the pandas 2.0 release) was actually a reason for some patches in “real-life” and we can see them nicely on prefix.dev! The read pandas pin of xarray (pandas >=1.4) was replaced with pandas >=1.4,<2 because it turned out that xarray was not compatible with the latest pandas release.
Outlook
We’ve discussed how conda-forge does “repodata-patching”, one of the very special features that help with the maintenance of such large repositories. We also had a quick look at yanking, and how prefix.dev helps visualizing all these changes on the repository. At prefix.dev we try to further increase the package compatibilities by researching some static analysis tools to build a database of “symbols”. You can find an earlier blog post on the topic here: The Python Packaging Debate.